Voorkom een AI-fiasco door anders te programmeren
- De kwaliteit van veel AI-systemen is slecht
- Weinig aandacht voor software engineering bij data scientists
- Oplossing is onderhoudbaarheid en testdekking blijven meten en verbeteren
- Lees ook: Kwaliteit software gaat mank op AI, open source en vaardigheden



Kunstmatige intelligentie (AI) is in opkomst. Veel AI/bigdatasystemen blijken echter te kampen met ernstige kwaliteitsproblemen, vooral op het gebied van onderhoudbaarheid en testbaarheid. Rob van der Veer en Asma Oualmakran belichten de typische kwaliteitsproblemen van AI/ bigdatasystemen, analyseren de achterliggende oorzaken en geven aanbevelingen om een AI-fiasco te voorkomen.
De SIG benchmark is een database met broncode van vele duizenden softwaresystemen afkomstig van Open Source en van SIG-klanten. We zien dat AI/bigdatasystemen significant minder onderhoudbaar zijn dan andere systemen: 73% van de AI/big data systemen scoort onder het gemiddelde in de SIG benchmark. De belangrijkste oorzaak zit in de kwaliteitseigenschappen ‘Unit Size’ en ‘Unit Complexity’: veel lange stukken complexe code.
Gelukkig bestaan er ook AI/bigdatasystemen met een hoge onderhoudbaarheid, zoals de benchmark duidelijk laat zien. Dit toont aan dat het niet onmogelijk is om onderhoudbare AI/big data systemen te bouwen.
Lange en complexe stukken code zijn moeilijk te analyseren, moeilijk aan te passen, moeilijk te hergebruiken en moeilijk te testen. Hoe langer een stuk code is, hoe meer verantwoordelijkheden het omvat en hoe complexer en hoe meer beslissingspaden er zijn. Dit verklaart waarom het vaak onmogelijk is om testen te maken die alles afdekken. Dit testbaarheidsprobleem wordt aangetoond door de dramatisch kleine hoeveelheid testcode. In een typisch AI/bigdatasysteem is 2% van de code testcode, terwijl dit voor de benchmark normaliter 43% is.
Lage onderhoudbaarheid maakt het steeds kostbaarder om veranderingen door te voeren, en het risico op het introduceren van fouten groeit zonder de juiste mogelijkheid om deze fouten te detecteren. Na verloop van tijd veranderen gegevens en de vereisten, en de aanpassingen daarvoor worden dan typisch ‘opgeplakt’ in plaats van goed ingebouwd, waardoor het alleen maar ingewikkelder wordt. Bovendien wordt overdracht naar een ander team minder haalbaar. Met andere woorden: typische AI/bigdatacode heeft de neiging een blok aan het been te worden.
Gebrek aan abstractie
Waardoor ontstaan de lange en complexe stukken code? Dergelijke problemen zijn meestal het gevolg van niet-gefocuste code (code met meer dan één verantwoordelijkheid) en een gebrek aan abstractie: nuttige stukken code worden niet geïsoleerd in afzonderlijke eenheden. In plaats daarvan worden ze gekopieerd, met veel duplicatie tot gevolg, waardoor aanpasbaarheid en leesbaarheid in de problemen komen.



Gerelateerde artikelen
Ontbreken van testcode
Een van de redenen waarom testcode van functies ontbreekt in AI/bigdatasystemen is dat de engineers vertrouwen op integratietesten, die voor dit soort systemen kunnen worden uitgevoerd door de correctheid van het AI-model te meten. Als het model slecht presteert, kan dit duiden op een fout. Maar hoe bepaal je wat slecht presteren is? Het probleem met deze aanpak is tweeledig:
- Door het gebrek aan testcode van functies (‘unit tests’) is het niet duidelijk waar een probleem zich bevindt.
- Het model kan goed presteren, maar er kan toch een fout zijn die voorkomt dat het model nog veel beter presteert.
Bijvoorbeeld: een model om de verkoop van drankjes te voorspellen gebruikt het weerbericht als input en laten we zeggen dat het 80% correct scoort. Stel dat er een fout is waardoor de temperatuur altijd nul aangeeft, dan kan het model daardoor geen 95% score behalen. Zonder goede testcode wordt dit nooit gevonden.
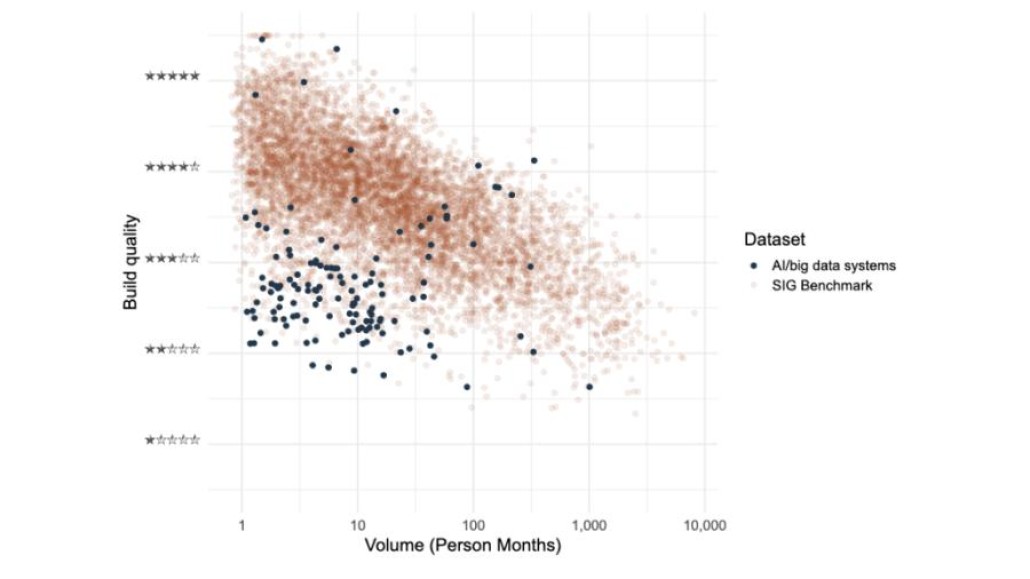
© SIG
Figuur 1: Onze selectie van AI/big datasystemen uit de SIG benchmark werd samengesteld door systemen te selecteren die zich richten op statistische analyse of machine learning. In deze grafiek staat op de X-as de systeemomvang gemeten in maanden programmeerwerk en op de Y-as de onderhoudbaarheid gemeten in 1 tot 5 sterren. Drie sterren is gemiddeld.
Oorzaak
Wat zien wij als achterliggende oorzaak van de problemen met de codekwaliteit van AI/big data?
- Programmeren in het lab: data scientists zijn heel efficiënt in ad hoc experimenteren om te komen tot een werkend AI-model - niet met de intentie om iets op te leveren dat voor langere tijd in productie moet gaan. Hun werk is zo ingericht dat ze in principe klaar zijn als het model werkt. Op dat moment is er geen echte stimulans voor de data scientist om code te gaan verbeteren. Er is ook nauwelijks testcode, dus als je code verandert, dan loop je het risico dat het niet meer werkt, zonder dat je het merkt. Het is niet alleen het werkende model dat opeens onderhoudbaar, overdraagbaar, schaalbaar, veilig en robuust moet zijn – ook alle code die heeft geleid tot het model moet langere tijd mee kunnen.
- Datascience-onderwijsprogramma's richten zich meestal meer op data science en minder op best practices voor software engineering.
- Traditioneel bieden datascience-ontwikkeltools weinig ondersteuning voor best practices op het gebied van software engineering. R en Jupyter notebooks bijvoorbeeld zijn gebaseerd op een stapsgewijze one-shotbenadering, die geschikt is voor experimenten maar niet voor onderhoudbare software. En sommige datascience-talen missen krachtige abstractie- en testmechanismen.
- Het SQL-patroon is vaak het standaardparadigma voor databewerking. Dit patroon komt neer op het werken met datasets die samengevoegd zijn en veel opeenvolgende bewerkingen op veel velden tegelijk. Bij AI/big data vertegenwoordigt dit een groot deel van het programmeerwerk (75-90%) [1] en het heeft zijn onderhoudbaarheidsuitdagingen waarvoor de oplossingen vaak onbekend zijn bij data scientists. Data scientists vinden dit het minst leuke deel van het werk en het moeilijkst[2].
Voor AI/bigdatasystemen komen wij in de praktijk meestal teams tegen met voornamelijk data scientists. Wanneer we met hen werken, zien we dat ze gefocust zijn op het maken van werkende analyses en modellen, terwijl ze vaak een aantal best practices op het gebied van software engineering ontberen, wat typisch leidt tot de onderhoudbaarheidsproblemen.
Voor AI/bigdatasystemen komen wij in de praktijk meestal teams tegen met voornamelijk data scientists. Wanneer we met hen werken, zien we dat ze gefocust zijn op het maken van werkende analyses en modellen, terwijl ze vaak een aantal best practices op het gebied van software engineering ontberen, wat typisch leidt tot de onderhoudbaarheidsproblemen.
Hoe nu verder?
Allereerst is het aan te bevelen de onderhoudbaarheid en de testdekking van AI/bigdatasystemen continu te meten en te verbeteren. Datascienceteams krijgen dan direct feedback over de kwaliteit van hun werk. Wat ook helpt, is data scientists en software engineers te combineren in teams. Dit werkt op twee manieren:
- Data scientists kunnen dan worden gecoacht om code te schrijven op een meer toekomstbestendige en robuuste manier. Zij zullen dit omarmen als ze eenmaal zien hoe zij er in hun dagelijkse werk van profiteren.
- Aan de andere kant is het goed om engineers die nieuw zijn in data science te laten leren van de krachtige paradigma's en tools die beschikbaar zijn voor AI en big data. Zo versterken de teamleden elkaar.
Het is belangrijk om AI te zien voor wat het is: software, met een aantal bijzondere eigenschappen. Dat is ook de benadering van de nieuwe ISO/IEC standaard 5338 voor AI engineering. In plaats van een heel nieuw proces neer te zetten, bouwt deze standaard voort op het al lang bestaande raamwerk voor de software levenscyclus (de 12207 standaard). Er zijn in organisaties typisch al bewezen voorzieningen en best practices die alleen maar te hoeven worden aangepast voor AI: versiebeheer, testen, devops, kennismanagement, documentatie, architectuur, etc. Ook dient AI te worden opgenomen in de activiteiten voor security en privacy – denk bijvoorbeeld aan pentesten. Ook op die gebieden heeft AI speciale uitdagingen[3]. Door deze inclusieve aanpak van software engineering kan AI verantwoord uit het laboratorium groeien en een fiasco worden voorkomen.
Meer onderzoeksresultaten en code-voorbeelden kunnen worden gevonden in het SIG 2023 benchmark rapport: https://www.softwareimprovementgroup.com/publications/2023-benchmark-report/
Referenties
[1] Software Engineering for Machine Learning: A Case Study”, 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE- SEIP),Amershi et al. Microsoft
[2] Software Engineering for Machine Learning: A Case Study”, 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE- SEIP),Amershi et al. Microsoft
[3] Zie de OWASP AI security & privacy guide: https://owasp.org/www-project-ai-security-and-privacy-guide/
Reacties
Om een reactie achter te laten is een account vereist.
Inloggen Word abonneeVeel van wat genoemd wordt heeft niet zozeer met AI te maken. De geschetste situaties komen helaas veel te vaak voor bij het maken van programmatuur. Te weinig abstractie (overerving) waardoor veel "uitzonderingen" geprogrammeerd worden. Testen gebeurt pas als de code er is. Ook ontwerpen kunnen getest worden op mogelijke uitkomsten. Dat gebeurt nauwelijks. Ontkoppelen van software componenten waarbij resultaten worden overgedragen in plaats van specifieke functie aanroepen. Uit het artikel blijkt niet wat er nu zo anders is voor AI toepassingen.
Het klopt dat de geschetste situatie te vaak voorkomt bij het maken van programmatuur in het algemeen. Bij AI komt het alleen veel vaker voor - getuige de 2% AI testcode vergeleken met de gemiddelde testcode in de industrie van 43%. Het geadviseerde percentage is 80%. Daarnaast scoren AI systemen qua onderhoudbaarheid veel lager dan gemiddelde systemen in de industrie. Het artikel beschrijft wat er zo anders is voor AI op 4 vlakken in de paragraaf 'Oorzaak'