AI krijgt catastrofale contentcrisis voor de kiezen
Temidden van nuttige AI-toepassingen, twijfelachtig AI-gebruik en algehele hype rond kunstmatige intelligentie - gefocussed op generatieve AI (genAI) - doemt er een fundamenteel probleem voor AI op. Namelijk een crisis in de voedingsbodem voor AI-modellen: de content, waar modellen op getraind worden. Rechtszaken over auteursrechten lopen nog, maar contentaanbieders gaan al voor afschermen, betaling vragen, exclusieve deals sluiten én zelf AI gebruiken. Een contentcrisis komt eraan.
- Lees ook: Wees kritisch op de AI-hype


© Shutterstock
Wanneer is scrapen van content zonder expliciete permissie een schending van auteursrechten? Gerechtelijke uitspraken daarover zijn er, maar nieuwe situaties kunnen nieuwe jurisprudentie vereisen. Of daartoe leiden. Het scrapen van content voor hergebruik is één ding, waarover tegenwoordig wel duidelijkheid is: dat mag niet zomaar. Maar het scrapen van content voor het trainen van AI-modellen die dan wel/niet een eigen iets doen? Hoe eigen is de output van AI eigenlijk?
Tekst, beeld, code, forumposts
Aanklachten hierover zijn ingediend en grote bedragen staan op het spel. Ongeacht de uitkomst daarvan, in verschillende landen met mogelijk afwijkende regels en interpretatie daarvan, is er nu al wel sprake van veranderingen. Contentaanbieders komen terug op het openbaar online publiceren van hun waren. Enerzijds omdat ads-inkomsten niet meer zijn wat ze geweest zijn, maar anderzijds ook in reactie op contentgebruik voor AI-training.
Bij sommigen worden voorwaarden ingevoerd (in bijvoorbeeld robots.txt) die scrapende AI-bots moeten weren. Voor sommigen is er hulp van CDN-aanbieders (content distribution network) als Cloudflare. En sommigen tuigen registratiemuren op, of profijtgerichte paywalls. Het gaat hierbij niet alleen om contentproviders in de traditionele media-industrie, die tekst maar ook beeld aanbieden. Naast boekenschrijvers, krantenuitgevers en beeldbanken zijn er meer contentpartijen ‘in scope’. Het gaat bijvoorbeeld ook om waardevolle kennisreservoirs zoals programmeerhulpsite Stack Overflow en internetforum Reddit.
Hoewel er aan de classificering ‘waardevol’ wel één en ander valt aan te merken. Want wat was de bron van de pizzablunder die Google’s AI-chatbot Gemini in mei dit jaar maakte? Een van de geruchtmakende blunders die de techreus ertoe bracht om zijn AI-aangedreven search anders aan te pakken. Hoe kwam Gemini erbij om lijm te adviseren als ingrediënt op pizza’s, om te voorkomen dat kaas er vanaf glijdt? De bron was een grap van inmiddels twaalf jaar terug, in een forumpost op Reddit.
Grote contentdeals
Hetzelfde Reddit dat zakelijk sluw een groot contentcontract met Google heeft gesloten. Voor 60 miljoen dollar per jaar mag de searchgigant de forumsite benutten voor AI-input. Deze deal is een uitvloeisel van Reddits zoektocht naar (meer) inkomsten, waarvoor het begin 2023 al een betaalde, AI-gerichte API (application programming interface) introduceerde. Een soortgelijke AI-tolheffing is developersplatform (vraagbaak en antwoordenreservoir) Stack Overflow gaan doen.
")



Aanbieders en eigenaren van content staan in hun recht om bepaalde beperkingen voor gebruik op te leggen en om betalingen te vereisen. Garantie voor gelijke toegang hoeft daarbij helemaal niet gegeven te worden. Zo is de Google-deal van Reddit een exclusieve: de marktdominante zoekmachine is nu de enige manier om informatie te zoeken en vinden op de grote forumsite. Andere zoekmachines worden geblokkeerd.
AI in de ban, mensen in de ban
Saillant detail is ook dat contentaanbieders zelf AI omarmen. In het geval van bijvoorbeeld Stack Overflow biedt die een AI-tool om developers te helpen met hun werk. Ironisch genoeg heeft de vraag/antwoordsite zelf AI-antwoorden in de ban gedaan. Aanvankelijk was dat een tijdelijk verbod, vanwege de lage kwaliteit van AI-gegenereerde antwoorden op developmentvragen van mensen. Concreet: het risico van fouten.
Deze AI-kritische houding heeft Stack Overflow er niet van weerhouden om in mei dit jaar een contentdeal met OpenAI te sluiten. De Stack-deal voor het verkopen van trainingsdata leidde tot ophef onder developers, die hun antwoorden op programmeervragen niet zomaar aan OpenAI’s AI willen geven. Ophef waar Stack Overflow op heeft gereageerd door die ‘dissidenten’ te verbannen.
Daarna heeft OpenAI, maker van genAI-hypestarter ChatGPT, nog meer contentdeals gesloten, met grote uitgeverijen als Axel Springer, Condé Nast en The Associated Press (AP). Miljoenendeals voor formele toestemming om content te gebruiken die het AI-bedrijf al heeft gebruikt. Het groot geworden OpenAI kan zich dat nu wel veroorloven: het bedrijf heeft begin oktober een waarde van 157 miljard dollar bereikt.
Trainingsdata ‘droogt op’
Op het eerste oog klinkt dit misschien als een goedmakertje achteraf, of als een (preventieve) afkoopdeal voor eventuele rechtszaken over auteursrechten. Maar dergelijke contentdeals zijn eigenlijk niet gericht op het verleden, maar juist op de toekomst en de daar opdoemende contentcrisis. Door registratiemuren en paywalls, exclusieve deals en toenemend gebruik van AI voor contentcreatie dreigt de voedingsbodem voor volgende AI-modellen op te drogen.
Meer en meer AI-gecreëerde content - of dat nu tekst, beeld, video of code is - gaat meer en meer dienen als trainingsdata voor AI. Die dan weer meer AI-output geeft. Dit Ouroboros-effect waarbij AI z’n eigen staart opeet door content te herkauwen levert niet alleen meer eenheidsworst op. Wat op zichzelf al erg kan zijn. Maar de contentverschraling plus AI-feedbackloop kan ook leiden tot een complete ineenstorting. Wetenschappers waarschuwen voor een ‘model collapse’.
Wetenschappelijk onderzoek naar AI-modellen die zijn gevoed met recursief gegenereerde data wijst uit dat die modellen dan ‘inklappen’. AI-modellen ongefilterd laten leren van data die is gegenereerd door andere AI-modellen leidt tot een degeneratief proces, schrijven de onderzoekers in hun paper, gepubliceerd in wetenschapsvakblad Nature. Bij dat neergaande proces vergeten de AI-modellen na verloop van tijd wat de daadwerkelijke onderliggende datadistributie is. Oftewel: wat de data eigenlijk zijn.
Golden retrievers en beige brei
De nu zo populaire AI-modellen doen in wezen slechts aan patroonherkenning. De input van trainingsdata ‘leert’ ze die patronen, waarna die worden gekoppeld aan opdrachten (prompts) van gebruikers. De output is vervolgens een oplepeling van wat statistisch gezien, volgens gedetecteerde patronen, het meest waarschijnlijk is. Daarbij ‘neigen’ AI-modellen echter naar de meest voorkomende zaken, legt TechCrunch uit. Het resultaat: eenheidsworst. Bij ‘AI-herkauwing’ van informatie raakt het vinden van patronen steeds verder vervuild, waardoor eenheidsworst iets heel anders kan worden.
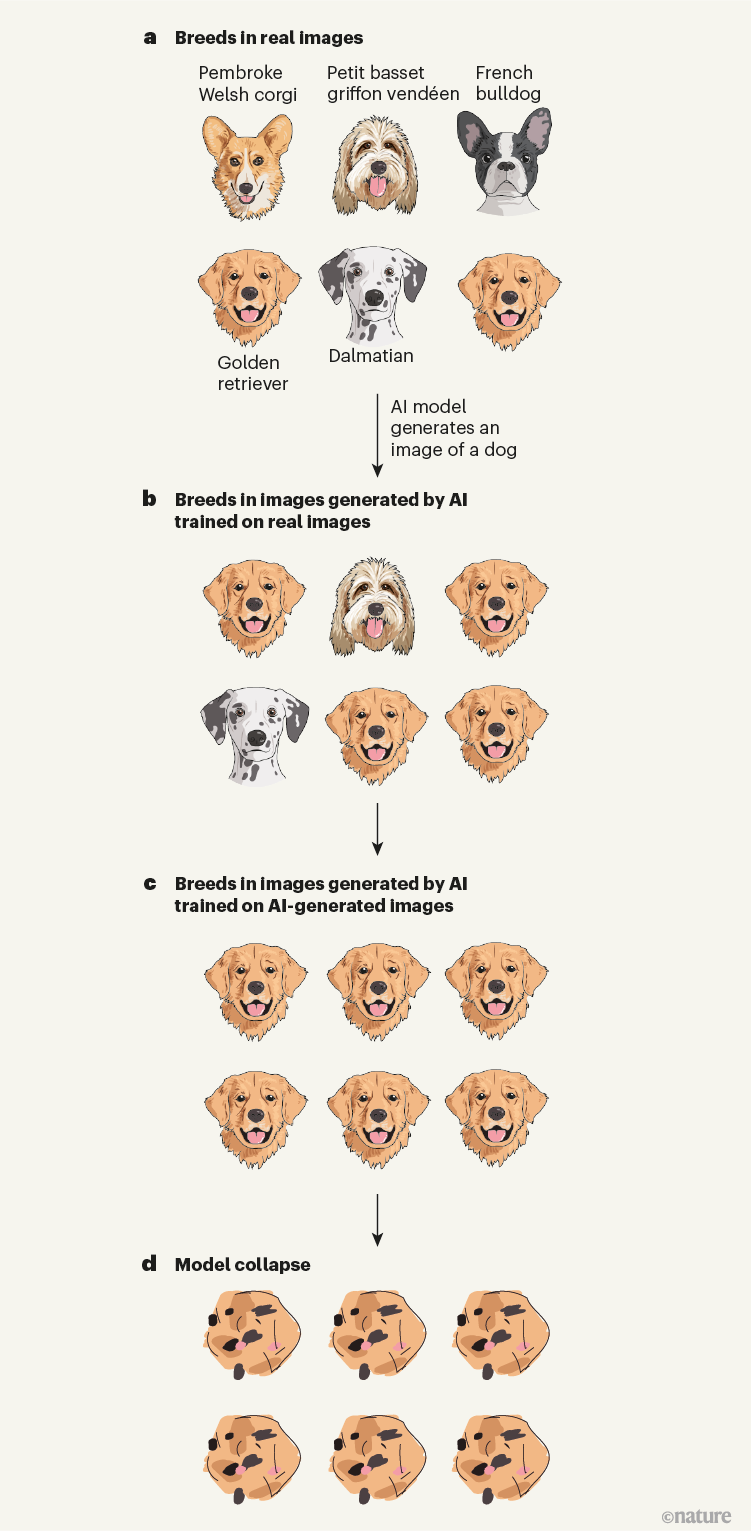
Het begeleidende artikel in Nature illustreert dit duidelijk: AI-beeldherkenning van honden levert in een eerste ronde prominentie op voor een veel voorkomende hondensoort, zoals een golden retriever. Die wordt in een volgende ronde dominant, daarna geheel overheersend en vervormt uiteindelijk tot een abstracte beige brei met wat zwarte vlekken erin. Het AI-model is dan ingestort, door de zelfgecreëerde contentfeedbackloop. Datadiversiteit, verse aanvoer, gecureerde content en meer menselijke bijsturing zouden dit kunnen voorkomen. Maar wie gaat dat doen en wat gaat daaraan verdiend worden?
{kind=link}
Het dode internet: van theorie naar realiteit
Het klinkt als een ‘conspiracy theory’ en is dat in den beginne ook slechts geweest. Namelijk de notie dat het internet is veranderd in een ‘dood netwerk’, waar mensen nauwelijks meer een rol spelen. Oorspronkelijk ging het om een paranoïde gedachte over nepcontent en beïnvloeding door kwaadwillende krachten achter de schermen. Later ging het om de zichtbare verandering dat het internationale netwerk der netwerken niet langer om mensen draaide, maar om content - en dat ten koste van alles, zo schreef Vox in 2015.
Deze fundamentele kwestie voor de media-industrie is echter tegenwoordig een veel bredere - maar nog altijd fundamentele - kwestie geworden. Eerst door de omarming van social media en recenter door de stormachtige opkomst van generatieve AI (genAI). De notie dat het internet dood is, wordt meer en meer realiteit en raakt daarbij veel meer sectoren, organisaties en mensen.
En bots, vergeet de bots niet. Want die hebben ervoor gezorgd dat het internet dood is. Zo luidt de theorie die in de praktijk duidelijk zichtbaar is. Bepaalde zinnetjes worden automatisch door bots gepost, geliked, aangevuld en weer doorgegeven. Bijvoorbeeld ‘I hate texting ..’ en dan aangevuld met een alternatieve manier om genegenheid te uiten, zo beschreef The Atlantic in 2021 de kwestie van het dode internet.
Complete legers van chatbots ‘praten’ met elkaar en drijven zo online-engagement aan. Alleen dus geen menselijke engagement. Een probleem voor de media-industrie en ook de ads-industrie. Maar door de opkomst van genAI, waarbij AI-modellen zijn getraind op online-content, is het dode internet ook een probleem voor vele anderen; die AI-toepassingen gebruiken, erop vertrouwen. Een bekende uitdrukking in de informatica en Informatietechnologie is: garbage in, garbage out. En dat lijkt nu aan de orde op het internet. Zie maar de dit jaar opgekomen golven aan AI-gegenereerde afbeeldingen van Jezus gevormd door garnalen. Een fenomeen met de naam ‘shrimp Jesus’.
In de theorie van het dode internet schuilt inmiddels dus een harde kern van waarheid, meent ook onderzoeksdirecteur Sander van der Waal van de Nederlandse stichting Waag Futurelab. Hij heeft afgelopen zomer in in tv-programma Spraakmakers gesteld dat we pas in de beginfase van het dode internet zitten. Van der Waal voorziet wel een tegenbeweging, maar die zal tijd nodig hebben om effectief te worden.
Magazine AG Connect
Dit artikel verscheen ook in AG Connect editie 6 2024. Wil je het blad ook ontvangen? Bekijk dan onze abonnementen.
Reacties
Om een reactie achter te laten is een account vereist.
Inloggen Word abonneeVoorbeeld content gepresenteerd conform het Ouroboros-effect is te vinden op https://photos.app.goo.gl/fy1rHpHSufG3aAnbA Deze interdisciplinaire wetenschappelijke manier van redeneren en bewijzen afgeleid uit hoe ons Universum is ontstaan zal de redding zijn tegen mogelijke gevaren en negatieve gevolgen van AI. Voorbeelden hiervan zijn de Quantum ICT-Systemen welke operationeel zijn. Op https://photos.app.goo.gl/F9qX6ekGRNwnNZGB7 , https://photos.app.goo.gl/JueuPvNMdZckVra17 en https://photos.app.goo.gl/XRcRX84H48EvhX9i9 is uitleg en een voorbeeld te vinden.