Automatisch rekeningen verwerken

Wie hielpen we met deze case?
Onze klant is een S&P500-bedrijf dat een grote vastgoedportefeuille heeft, die huisvesting biedt aan meer dan 100.000 gezinnen.
De uitdaging: nutsrekeningen efficiënter en met minder fouten verwerken
In de loop van een maand krijgt elke woning uit het portfolio specifieke water-, elektriciteits- en gasrekeningen, van bij verschillende leveranciers. Het verwerken van deze informatie en het maken van correcte betalingen levert een enorme hoeveelheid handmatig werk op. Het is vooral belangrijk dat alle rekeningen op tijd en correct worden afgehandeld, want één foute betaling kan desastreuze gevolgen hebben (stel je voor dat een gezin van het elektriciteitsnet wordt afgesloten).
In een concurrerende en snelgroeiende omgeving wilde de S&P500-klant de verwerking van nutsrekeningen zoveel mogelijk automatiseren, zodat ze alle rekeningen op tijd en binnen het budget konden verwerken, en tegelijkertijd het aantal fouten zoveel mogelijk kon beperken.
Bij eerdere pogingen experimenteerde de klant met Document AI en uptraining, wat helaas niet tot bevredigende resultaten leidde. Daarom nam de S&P500-klant contact met ons op.
Het doel: Ontwikkeling van een op maat gemaakt machine-learningmodel voor nauwkeurige voorspellingen en efficiënte schaalbaarheid
Omwille van de specifieke eisen van de klant overwogen we om een machine-learningmodel van topkwaliteit op maat te ontwikkelen dat:
- nauwkeurige voorspellingen kan leveren,
- kan schalen tot miljoenen facturen per maand,
- kan draaien met zo weinig mogelijk middelen en
- kan integreren met het gelabelde documentformaat van Document AI.
De oplossing: Bouwen van een aangepaste machine-learning oplossing voor DOC AI met Graph Neural Networks en HITL-ondersteuning
Devoteam G Cloud heeft veel ervaring met het bouwen van oplossingen op basis van de Document AI-suite. Om ontwikkelingsprocessen te versnellen, hebben we onze eigen accelerator gecreëerd die automatisch calls in batches bundelt en het gebruik van resources optimaliseert. De resulterende architectuur is hieronder afgebeeld:
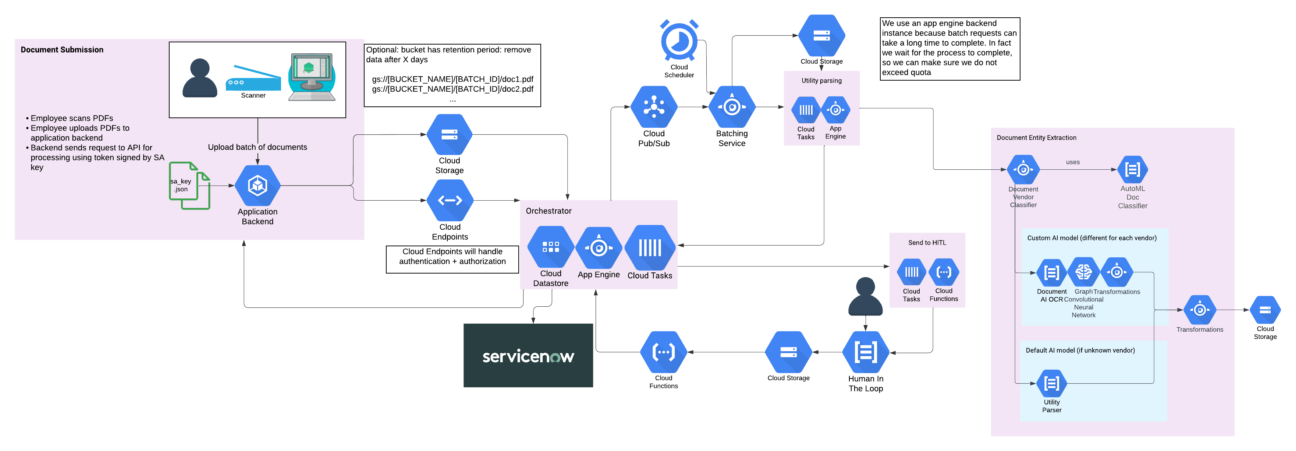
Het is dagelijks getest bij verschillende van onze klanten en kan honderden miljoenen documenten per maand verwerken.
Voor dit project moesten we rekening houden met een typische Document AI-workflow waarbij het proces toestaat om een handmatige verificatie te maken via Human-in-the-Loop (HITL). Daarom gebruikt onze aangepaste machine learning-oplossing via HITL gelabelde documenten als trainingsgegevens en produceert het voorspellingen die compatibel zijn met het Document AI-formaat. Deze vereiste functies, samen met alle functies van Document AI, maakt het voor ons mogelijk om terug te schakelen op een andere Document AI-processor, als die op een bepaald moment beter presteert dan onze aangepaste modellen.
Voor het aangepaste machine-learningmodel hebben we gekozen voor Graph Neural Networks, waarbij elk node een woord in een document voorstelt, en de randen links zijn naar de dichtstbijzijnde woorden in het document in de vier kardinale richtingen. Elk node bevat verschillende aangepaste kenmerken, met name een inbedding van de tekst zoals we in eerdere projecten hebben gedaan. Onze oplossing is dus gebaseerd op een taalmodel, dat tekst in een document begrijpt, en op een structureel model, dat de relatieve posities van de teksten in een document begrijpt.
Ten slotte gebruiken wij Vertex AI Vizier, de black-box hyperparameter tuning service van Google Cloud, waarmee wij in enkele uren de optimale configuratie voor ons aangepaste model kunnen vinden en de best mogelijke prestaties kunnen bereiken.
De methode: Gefaseerde aanpak en actief leren verhogen efficiëntie bij het verwerken van facturen voor S&P500-bedrijf met veel leveranciers
Aangezien het S&P500-bedrijf met een groot aantal leveranciers te maken heeft, moesten we een gefaseerde aanpak volgen. In het begin van het project kostte het verwerken van de facturen meer tijd door het labelen van documenten. Om het proces te versnellen, gebruikten wij actief leren: de kennis die het model met een zeer geringe hoeveelheid trainingsgegevens heeft opgebouwd, kan worden benut om het labelen verder te versnellen, het model opnieuw te trainen en zo door te gaan tot we een bevredigende prestatie bereiken. De op deze leveranciers opgebouwde kennis stelt ons vervolgens in staat de inspanningen te concentreren op andere leveranciers en deze veel sneller op te starten.
Zoals altijd is dit machine-learningproject grotendeels gebaseerd op de Vertex AI-productsuite van Google Cloud. Hiermee konden we elke stap van ons machine-learningproject afhandelen, van gegevensverkenning tot modelimplementatie en monitoring. Dankzij de mogelijkheden ervan konden we veel sneller experimenteren met modellen en verschillende architecturen, waardoor we aan alle eisen van de klant konden voldoen.
Het resultaat: 6x minder tijd nodig om documenten te labelen door de oplossing op maat
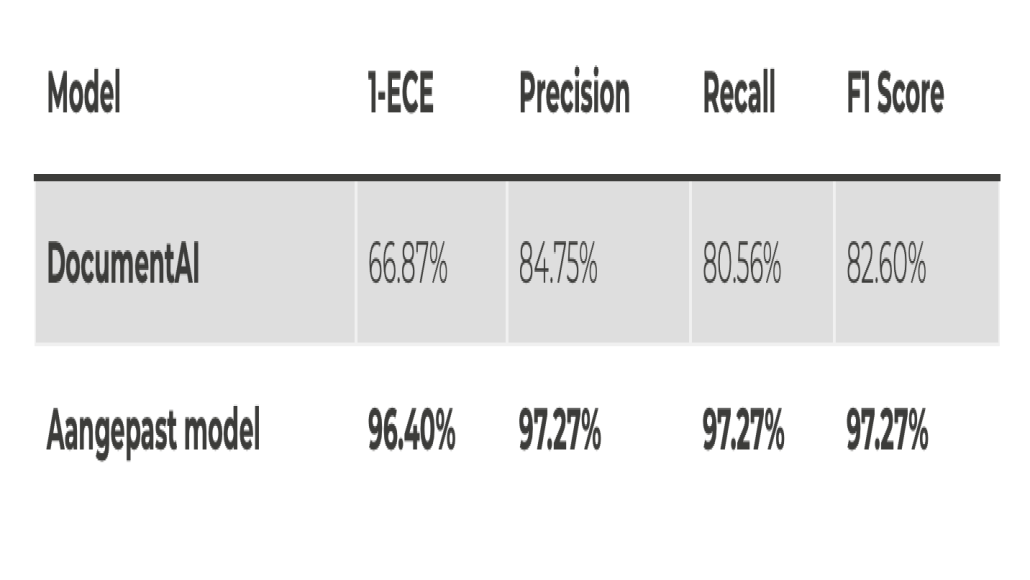
Om de voorspellingen van onze gemaakte modellen te evalueren, gebruiken we de F1-score. In een notendop bestaat de F1 score uit twee delen: precisie en recall. Precisie is een maatstaf voor hoe nauwkeurig de voorspellingen zijn. Recall is een maat voor de volledigheid van de voorspellingen. Om de F1 score te verkrijgen, nemen we het harmonisch gemiddelde van de precisie- en recallscores. Dit helpt te beoordelen hoe goed de voorspellingen in het algemeen zijn, omdat het rekening houdt met zowel nauwkeurigheid als volledigheid.
Aan het eind van het project bereikten we dankzij Vertex AI Vizier, dat de parameters van onze modellen optimaliseerde, een F1-score van 97,27%. In vergelijking met de prestaties van Document AI betekent dit dat het bedrijf dankzij onze aangepaste oplossing ongeveer 6x minder tijd kwijt is aan labelen.
Een F1-score van 82,6% is al geweldig en voldoende om in productie te draaien, maar kan verder worden verbeterd met aangepaste modellen voor machinaal leren, aangepast aan de specifieke uitdagingen van die klant.
Nu de oplossing in productie is, heeft het S&P500-bedrijf meer dan 15 verschillende leveranciers aan boord die tot 20.000 documenten per maand vertegenwoordigen. Terwijl het aantal verwerkte documenten blijft groeien, profiteert het team nu al van de oplossing in hun dagelijkse werkzaamheden, waardoor hun werklast veel lichter wordt en het aantal fouten tot bijna nul is teruggebracht.
Verwerkt jouw bedrijf een groot aantal documenten handmatig?
Verhoog de operationele efficiëntie, verminder de handmatige inspanningen en versnel de bedrijfsinnovatie met DocAI en een oplossing op maat van jouw noden.
Reacties
Om een reactie achter te laten is een account vereist.
Inloggen Word abonnee