Achtergrond
Cloud
volgen
volgend
PRO
31 oktober 2018
leestijd 5 minuten
0 reacties
43 seconden uitval gaf GitHub 24 uur storing
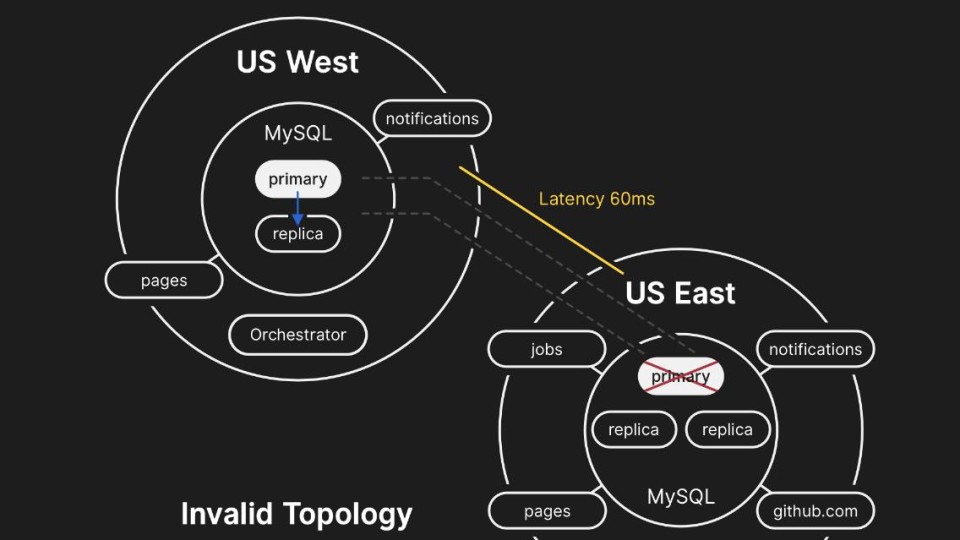
GitHub gaat met de billen bloot in een post mortem over de grote storing die de repositorysite eerder deze maand heeft getroffen. De oorzaak is een uitgevallen verbinding tussen twee locaties: beide aan de Amerikaanse oostkust. Na 43 seconden was die uitval weer hersteld, maar daarna volgde 24 uur en 11 minuten aan storing wereldwijd.
© GitHub
© GitHub
Lees dit PRO artikel gratis
Maak een gratis account aan en geniet van alle voordelen:
Toegang tot 3 PRO artikelen per maand
Inclusief CTO interviews, podcasts, digitale specials en whitepapers
Blijf up-to-date over de laatste ontwikkelingen in en rond tech
Word gratis lid en lees verder
Bevestig jouw e-mailadres
We hebben de bevestigingsmail naar %email% gestuurd.
Geen bevestigingsmail ontvangen? Controleer je spam folder. Niet in de spam, klik dan hier om een account aan te maken.
Sluiten
Er is iets mis gegaan
Helaas konden we op dit moment geen account voor je aanmaken. Probeer het later nog eens.
Sluiten
Maak een gratis account aan en geniet van alle voordelen:
Toegang tot 3 PRO artikelen per maand
Inclusief CTO interviews, podcasts, digitale specials en whitepapers
Volg je favoriete topics
Heb je al een account?
Log in
Maak een gratis account aan en geniet van alle voordelen:
Toegang tot 3 PRO artikelen per maand
Inclusief CTO interviews, podcasts, digitale specials en whitepapers
Volg je favoriete topics
Heb je al een account?
Log in